In this blog post, we will explore a solution for optimising a FileMaker app that handles large amounts of data. We will address the challenges of data storage, file corruption, and performance degradation when dealing with historical data.
By leveraging cloud storage and serverless computing, we can offload and query this data efficiently, ensuring better performance and scalability.
[Editor’s note: Content from this blog post has been shared in Fabio’s presentations at dotfmp Berlin 2023 and FM-DiSC’s July 2023 meetup.]
The Challenge of Handling Large Amounts of Data
When dealing with FileMaker solutions that generate thousands of records daily, especially during peak periods, storing and managing this data can become challenging. Over time, the accumulation of millions of records can lead to increased file sizes and potential file corruption issues.
Additionally, running reports on large datasets may impact performance, especially when using the application over a wide area network (WAN).
Pros and Cons of Keeping Data in FileMaker
There are advantages to storing data within the FileMaker solution, such as easy accessibility, control, and the ability to perform searches and queries directly within FileMaker.
However, there are downsides, including the continuous growth of file sizes, reduced performance for older and new reports, the risk of file corruption, lengthy data recovery processes, and potential difficulties when making changes to large files, especially in a WAN environment.
Workarounds for Handling Large Data Sets
Developers have attempted various workarounds to address these challenges. Some have duplicated files by appending the year to the file name or allocated separate FileMaker Servers to store archived solutions.
Others have integrated SQL databases like MySQL, SQL Server, or PostgreSQL via External SQL Sources (ESS).
However, these approaches often introduce additional complexity, maintenance overhead, and performance issues.
Offloading Historical Data with Cloud Storage
To mitigate these challenges, we propose offloading historical data that is no longer required in the short term to persistent storage, such as AWS S3 (Simple Storage Service).
AWS S3 offers high availability, additional data protection options, and the ability to store data in various formats like CSV or JSON.
Querying Data with Amazon Athena
To query the data stored in S3, we can utilise Amazon Athena, a serverless query engine.
Athena enables analysis of unstructured, semi-structured, and structured data stored in S3 using ANSI SQL queries.
It utilises open-source, in-memory, distributed SQL engines like Trino and Presto to handle complex analysis without the need for provisioning or configuration.
Integration with FileMaker via Microservices
To interact with AWS S3 and Amazon Athena from a FileMaker solution, we can create a microservice that exposes APIs.
Amazon API Gateway securely exposes endpoints that can be invoked from FileMaker, and AWS Lambda (serverless) handles the requests and routes them accordingly. By using the Serverless Framework and adopting the “Infrastructure as Code” (IaC) approach, the entire stack and resources can be deployed with ease.
Architecture Overview
In our proposed architecture, a FileMaker script exports daily created or modified records to a data file in JSON format.
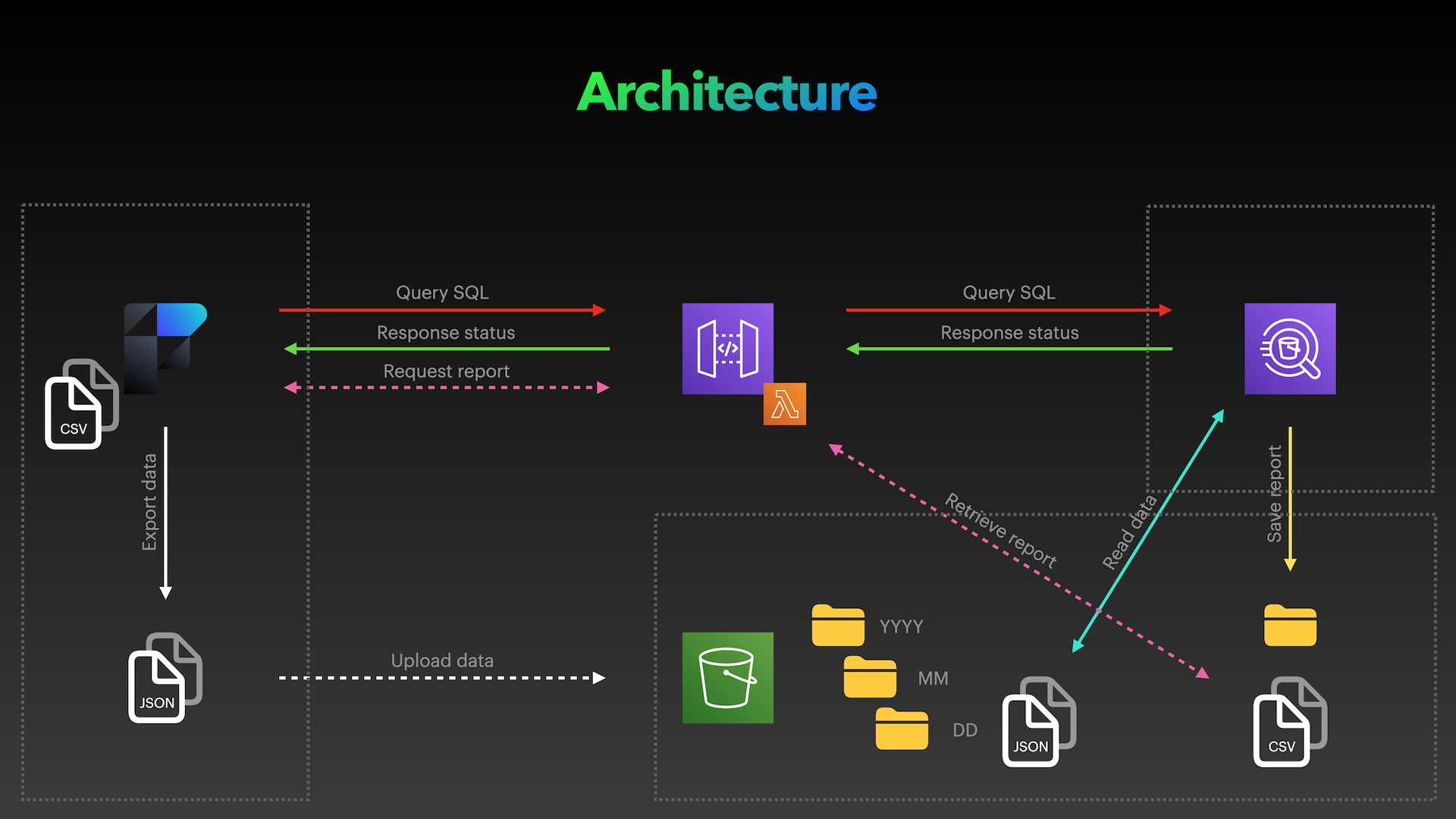
Another script uploads this file to an Amazon S3 bucket organised by year, month, and day. Maintenance procedures can then be performed on the FileMaker app, such as deleting unnecessary historical data, keeping the database size manageable, and ensuring consistent performance.
When querying data, FileMaker sends an SQL statement request to the microservice, which triggers a query execution in Amazon Athena. The results are stored in a separate folder in CSV format, and FileMaker can retrieve the file using a pre-signed URL.
Benefits and Considerations
Offloading historical data to cloud storage and leveraging serverless computing offers several benefits. It reduces file size, improves performance, ensures data accessibility, and enables integration with popular data visualisation tools like Tableau and Amazon QuickSight.
However, it is essential to consider the associated costs, such as storage in Amazon S3, data scanning in Amazon Athena, and usage of Lambda and API Gateway.

Conclusion
By offloading historical data to cloud storage and utilising serverless computing, FileMaker solutions can effectively handle large datasets, improve performance, and maintain data integrity. The integration of AWS S3, Amazon Athena, and FileMaker through a microservice provides a scalable and efficient solution. Developers can build upon this approach to enhance audit logs and explore further possibilities for optimising FileMaker applications.
Additional Resources
To learn more about microservices, AWS S3, Amazon Athena, AWS Lambda, and data visualisation tools, consider exploring the following resources:
- AWS Microservices
- An Introduction to Microservices
- AWS S3
- Amazon Athena & Interactive SQL
- AWS Lambda [Serverless]
- Amazon QuickSight
- Tableau
- Beezwax Blog