The dependency inversion principle is one of the cornerstones of object-oriented programming. Without it, there is no object-oriented design. It’s that important.
What amazes me about this principle is that people can spend years working with an object-oriented language and never learn about it, never take the next step towards becoming a senior developer, especially if working with dynamically typed languages.
Different Types of Dependencies
Before I talk about Dependency Inversion, I need to talk about dependencies. In an object-oriented context, there’s a dependency when an object knows something about other object. It’s that simple.
Let me show you an example:
class Post {
constructor () {
this.category = new Category(1, "General")
}
}How many dependencies are there in the code above? It knows the name of the Category class, so that’s one. It knows the class responds to constructor, it knows the arguments constructor requires, and it also knows the order of those arguments. So that’s a total of four dependencies.
Here is a list to help you recognize dependencies, taken from the awesome Sandi Metz’s book: Practical Object Oriented Design in Ruby:
- When an object knows the name of another class
- When an object knows the name of a message that it intends to send to someone other than
self - When an object knows the arguments that a message requires
- When an object knows the order of those arguments
Let’s see another example:
class Cat extends Animal {
constructor (owner) {
this.owner = owner
}
}How many dependencies are there in the class above? It knows Animal, so that’s one. Notice that because owner is injected, we don’t know its class, so there’s no dependency there. We still don’t send it any messages, so that still doesn’t count as a dependency. Cat only has one dependency so far. The moment we send a message to owner, we add a new dependency.
Knowing when to use composition (example #1) and when to use inheritance (example #2) can be tricky. Here’s a little list to help you out:
- When X is-a Y: Inheritance
- When X has-a Y: Composition
- When X behaves-like-a Y: Interface/Abstract Class/Duck Type
It’s important to note that inheritance is not for sharing code. It’s for specialization. Be careful of inheritance when the thing that changes is a very small portion of the superclass.
Just Tell Me The Principle Already
Okay, okay, but this principle is better understood by using an example. So let me show you instead.
Let’s start with example #1 from before:

Notice the direction of the arrow, it goes from Post to Category, because a Post has-a Category.
In non-OOP languages, programs are organized from most generic to most specific. So high level functions call lower level functions, and lower level functions call even lower level functions, and so on.
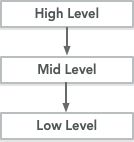
Even modern object-oriented software is designed like that sometimes. And sometimes it’s not a big deal.
But what happens when the low level things we depend on change very often? Whenever we change a low level thing, we also have to update the mid level one, and maybe we also have to change the high level one, too! This is why there’s a maxim in OOP: Always depend on things whose interface change less than you.
But, how can we invert the dependency? How can we make the arrow go the other way around? The trick is to use interfaces.
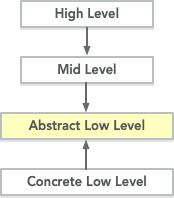
Interfaces, or abstract classes, are just a set of messages a concrete object must answer to. Abstract classes cannot be instantiated, only extended.
What happened there? Because our concrete class extends from the abstract class, it depends on it. So the arrow goes from concrete to abstract. And now, mid-level can depend on the abstract implementation instead.
This is good, because abstract changes less than concrete, and it gives us a way to invert the dependency.
This leads us to the gist of the Dependency Inversion Principle: Depend on abstractions, not concretions.
The tricky thing about abstractions is that in dynamically typed languages, such as JavaScript and Ruby, they are hidden. An abstract class might just be a regular class, that we all agree we won’t instantiate and just extend, and its methods are either trivial or empty.
Below is an example Iterable abstract class in JavaScript:
class Iterable {
get next () { throw new Error('Not implemented') }
get hasNext () { throw new Error('Not implemented') }
}Classes can extend this behavior if they want to, and because it’s so simple and high-level, it’s rare that it will ever change.
But it might be even more subtle, it might not even exist at all! Instead it’s just implicit duck:
class Post {
// ...
toString () { return this.title }
}
class Comment {
// ...
toString () { return this.body }
}In the example above, both classes answer to toString, but this is implicit. There’s no Stringable interface; it’s there only in spirit.
This is why naming is a big deal, particularly in dynamic languages, where you don’t have the extra type information that gives you that extra context.
function (model) { // bad
return `Welcome ${model}`
}
function (stringable) { // better
return `Welcome ${stringable}`
}Plugins
We all know what plugins are, simple extensions to existing software. If you have a text editor, you might install a plugin to hightlight text in some way, or be able to export to PDF or whatever. They extend the functionality of existing software.
This is what a plugin design looks like:

The software can exist without the plugin, but the plugin cannot exist without the software.
Now consider a typical Web Application that uses any modern framework, such as Rails, Django or Laravel.
It might look like this:
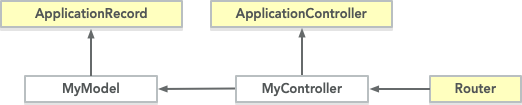
The example uses Rails’ classes, but it works similarly for any framework.
Look familiar? In this case, your application’s controller could not exist without ApplicationController, same for your model, because your application is a plugin of the framework.
This has its advantages and disadvantages. If the framework doesn’t change much, it’s not a big deal. If it changes a lot, you will need to make significant changes to keep your application up to date.
Also, you are locked into a particular framework. You can’t easily just take your application, or part of it, and use it in a different ecosystem, like a CLI or desktop application, or even a different version of the same framework.
The sad truth is that many Rails apps (and apps using similar frameworks) end up tightly coupled with the framework, with fat models and fat controllers, as we say in Rails-world.
Decoupling
Your application should be front-and-center. Not the framework. The business logic of your application should not depend on things like which database you are using, nor which framework.
We are now stepping into the realm of design. Don’t worry if this sounds all too abstract, the important part here is to understand how Dependency Inversion helps us decouple our application’s core from the implementation details.
There are some design patterns that help with this. A popular one is Clean Architecture, by the famous, loved-and-hated Uncle Bob. Another alternative, which is fundamentally the same, is Hexagonal Architecture.

In that design, the application core lives at the center, surrounded by Ports. Ports are simply interfaces, where Adapters are concrete implementations.
That way, the application looks like this:
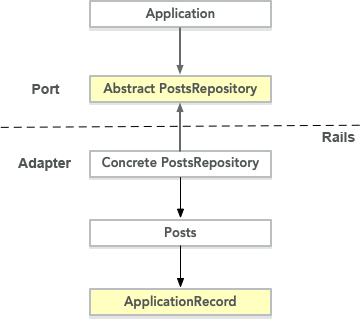
We draw a line: We cannot have an arrow going from the Application to Rails, because if we did, our Application would depend on Rails. Rails can cross the line, though, because it’s a plugin to our Application.
Drawing lines and organizing arrows like that is what object-oriented design is all about.
Notice that now, because our application depends on abstractions, we can replace the concrete implementation at any time. We could move it to a CLI application, and use ROM instead of Rails, and it would work. This way, the framework is a plugin of our application, not the other way around.
Yeah, but is it worth it?
The real-world answer is: It depends. Frameworks like Rails pack a lot of magic. Change a single thing and it goes from “everything just magically works” to painfully struggling at each step.
At the time of writing, I think for Rails in particular, the best is to use Interactors together with Form Objects. There are a few implementations already that can make life easier.
Covering the interactor design pattern is out of the scope for this blog post (maybe a future post?), but with interactors, a regular Rails app would look like this:
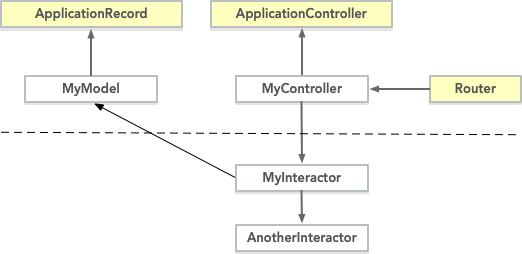
It’s not perfect, we are still tied to Rails–there are ways we can decouple it if we really want to, not without considerable struggle with the framework though–but at least we have a clear place for our application’s core: Below that line, in app/interactors.
If you want to implement Hexagonal Architecture, and be independent of the framework/database implementation because that’s a requirement, then another ecosystem with less magic might be more suitable. Magic comes at a cost.
Conclusion
It doesn’t matter if you understood the details about the example design patterns or not. They are there only to illustrate a point, and show you how to think about software design.
The gist of it is that Dependency Inversion is important, it can be accomplished with interfaces/abstract classes/duck typing, and it’s fundamental for Object Oriented Design.
You can apply this to everything, from refactoring a few classes to a whole application (including hexagonal design).
I think the most important thing, though, is that it helps you get used to thinking about code at a higher level: Your application is not just code, it’s also the relationships and organization between all the different actors in your code.
It makes a big difference when your application design is actually on purpose, and not just a random result of pumping out code to add features and fix bugs. Well-designed software can be easily changed and maintained. Without design, all software is doomed to collapse under its own weight, given enough time.
Note that too much design can also be bad. Hexagonal Architecture is an overkill for a simple blog website. That’s why it’s important to understand design, be flexible, and find the ideal solution in a case-by-case basis. There is no silver bullet when it comes to software. That’s why it’s hard!
I hope this helped make things clear. Cheers!
— Fede
One thought on “OOP Fundamentals: The Dependency Inversion Principle”