There are entire books written on testing. And it surely feels more an art than a science. My approach is similar to Kent Beck’s:
I get paid for code that works, not for tests, so my philosophy is to test as little as possible to reach a given level of confidence (I suspect this level of confidence is high compared to industry standards, but that could just be hubris). If I don’t typically make a kind of mistake (like setting the wrong variables in a constructor), I don’t test for it. I do tend to make sense of test errors, so I’m extra careful when I have logic with complicated conditionals. When coding on a team, I modify my strategy to carefully test code that we, collectively, tend to get wrong.
https://stackoverflow.com/a/153565/1015566
He goes on to add that different people will have different strategies and, at the end of the day, you just have to do what works best for you and your team. Extremely practical, and the approach I personally follow.
This won’t be a detailed post on every possible topic on tests and testing in Object-oriented Programming (OOP). There are many books about that already. Instead, this article will cover the basics of testing, so you understand how and why we test, and you can adapt it to your own needs.
Note that I will use the words spec and test interchangeably. Test comes from TDD and spec comes from BDD, but they point to the same thing.
Another thing I’d like to make clear is that this is different from QA testing. QA includes automated testing (the topic covered in this post) as well as manual testing, and testing things like usability, user experience, etc. If you like to know more about any of these topics, please feel free to contact us!
Why We Test
Why do we test? If I had to answer this with one word, I’d say: Refactor. I test so I can have confidence when refactoring. And I constantly refactor. Refactoring helps keep the design of the application healthy, and a good design ensures that you will be able to add as many features as needed in a reasonable time.
An application without refactoring is doomed to fail, given enough time is put into it.
When coding on a team, I modify my strategy to carefully test code that we, collectively, tend to get wrong.
– Kent Beck
Have you ever worked on an application where you need to work on a feature, and you end up having to touch a big, ugly, messy method? And you know what you are doing is wrong. It just feels bad. What’s worse, you know how to make it better, extract smaller methods, maybe make a few new classes, but you end up not doing it.
Why? You don’t do it because you don’t feel safe doing it! Because there is no safety net if something goes wrong. And like we all know, if there is a chance for something to go wrong, it will go wrong. Especially in software.
Tests are there to help us check for regressions. If we break something, tests should complain.
If we break something, tests should complain.
Working with a good test suite, you can feel confident when refactoring code. If you don’t have a good test suite, then refactoring is risky, and nobody ends up doing it.
That alone, is in my opinion more than enough reason to have tests.
What To Test?
Like Kent Beck stated, we want to test things we know we can miss, not trivial things. What to test exactly comes from experience and lots of practice. With time, you know the kind of errors you, or your team, usually make.
For example, I like testing complex methods, which handle complicated business logic. I don’t mind trivial, small methods as much. I also like testing classes which are used in a lot of places, even if they seem simple. You can even use tools like churnalizer to help you get a sense of your codebase, and get an idea of what to refactor and what to test.
Broadly speaking, we can divide our tests in two big categories: Unit tests, and Integration tests.
Unit Tests
You can think of an object-oriented application as a graph. Each node represents an unit (most likely an object or a class), and the messages are represented by the edges/arrows.
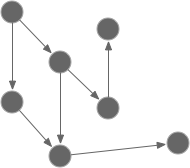
When your app is running, messages flow everywhere. Unit tests make sure each node works as expected. It tests the incoming as well as the outgoing arrows.
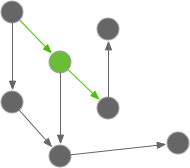
Most of the time, a unit is a class, but it’s not always like that. Sometimes it’s just a function or a group of tiny classes.
Incoming Messages
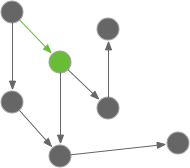
The incoming message is the easiest to test. When testing an object, an incoming message is simply a method in our object, together with its arguments.
class Greeter
def greet(name)
"Hello, #{name}!"
end
endIf we want to test the greet message, we can simply test the output:
describe 'Greeter' do
describe '#greet' do
it "shows the proper message" do
greeter = Greeter.new
expect(greeter.greet("Fede")).to.eq("Hello, Fede!")
end
end
endDon’t worry if you don’t know Ruby or RSpec; just think of it as pseudo-code. It’s only there to help you understand a point. It doesn’t need to be runnable.
Sometimes, our methods don’t return anything, but instead, change the object’s internal state. In that case, we simply assert the state after the operation is done:
it "can mark a TODO as 'done'" do
todo = Todo.new
todo.mark_as_done
expect(todo.status).to.be_done
endSomething we should avoid, are methods which both change the internal state (command) and return something (query). It’s called Command/Query Separation, and it makes things much easier in the long-run!
Outgoing Message
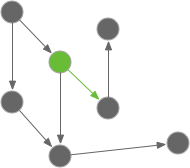
I’ve showed you how to test incoming messages, and the two general ways to test those. Now, how do we test an outgoing message? That is, what to do when our object under test uses another object to do it’s work?
class TwitterPoster
def post(tweet)
TweetService.new(api_key: 'some-key', api_secret: 'some-secret').post(tweet)
end
endMost of the time, our objects will use other objects to do work. In this case, TwitterPoster uses TweetService. Here, we have two different camps of thought:
- The unit under test should not talk to anybody else. Thus, we mock all the dependencies.
- The unit under test should use as much of the live system as possible. Thus, we should mock as little as possible.
Realistically, it doesn’t really matter which approach you use, as long as you test. That being said, there are some cases where mocking can’t easily be avoided. For example, in this case, TwitterPoster uses TweetService, which will make real HTTP requests to Twitter using real API credentials.
We don’t want to make real tweets when testing TwitterPoster. Because TweetService has its own tests, all we need to do is simply test the proper messages are being sent to it, and assume TweetService will do its thing.
Quoting Wikipedia, “mock objects are simulated objects that mimic the behavior of real objects in controlled ways”.
So in this case, we will create a dummy TweetService that responds to a predefined message. Remember, all we care when testing outgoing messages is that the message are properly sent. That’s all. The message itself will be tested in its own unit test, as an incoming message.
Taking a look at the code, though. It’s not easy to use a different service object. The TweetService class is hard-coded into TwitterPoster.
A good rule of thumb is that if it’s hard to test,
it’s not good object-oriented design
A good rule of thumb is that if it’s hard to test, it’s not good object-oriented design. So the first thing we have to do is refactor:
class TwitterPoster
attr_reader :service
def constructor(service)
@service = service
end
def post(tweet)
service.post(tweet)
end
endNow by injecting the service, not only do we remove the responsiblity of knowing the proper options to initialize it, we can also easily give our class a dummy object to test the messages get sent properly.
describe 'TwitterPoster' do
describe '#post' do
it 'sends #post to the service' do
service = double
allow(service).to_receive(:post)
poster = TwitterPoster.new(service)
poster.post("Hello!")
expect(service).to have_received(:post).with("Hello!")
end
end
endNotice that all we are testing is an outgoing arrow. If it got sent, we’re good. That’s all we care about. We will test that method in its own spec later on.
By the way, two important rules of thumb which can greatly help you are only mock objects you own, and never mock the object under test.
If you need to mock an object you don’t own, you can wrap it in your own object, and then mock that away. As for mocking the object under test, consider extracting whatever you are mocking into its own object and injecting it instead. Both those issues are pointing at design flaws in your application.
Only Mock Objects You Own
This is not a hard rule, it depends on your particular use-case. But quoting Mockito’s documentation, there are a few issues which can arise if we mock away a third-party object:
- Imagine code that mocks a third party lib. After a particular upgrade of a third library, the logic might change a bit, but the test suite will execute just fine, because it’s mocked. So later on, thinking everything is good to go, the build-wall is green after all, the software is deployed and… Boom
- It may be a sign that the current design is not decoupled enough from this third party library.
- Also another issue is that the third party lib might be complex and require a lot of mocks to even work properly. That leads to overly specified tests and complex fixtures, which in itself compromises the compact and readable goal. Or to tests which do not cover the code enough, because of the complexity to mock the external system.
Instead, the most common way is to create wrappers around the external lib/system, though one should be aware of the risk of abstraction leakage, where too much low level API, concepts or exceptions, goes beyond the boundary of the wrapper.
An example of wrapping a third-party object could look like this:
class MyTwitterService
# ...
def post(message)
authenticate
client.post(message)
end
private
def client
@client ||= new TwitterClient
end
def authenticate
client.authenticate(id: @id, secret: @secret) unless client.authenticated?
end
endIn the example above, we wrap TwitterClient, which would be a third-party object. We abstract the initialization and authentication process. We just expose a single post method, which will take care of everything.
We don’t want to simply mirror the third-party object, we want to expose as little logic as possible. Now, because we own this new MyTwitterService object, we can mock it away as usual.
Note that, when testing a critical third-party library, you might want to also add integration tests, to make sure the library is actually doing work. We’ll talk about integration tests soon.
Never Mock the Object Under Test
If we need to mock the object under test, it means our object is doing too much. It is a clear signal of bad design, and can be fixed by extracting the functionality you want to mock into its own object.
Consider this example:
class Mailer
def send(template, context)
template = find_template(template)
html = template.compile(context)
send_mail(html)
end
# ...
def send_mail(html)
# sends the actual email
end
endWe clearly don’t want to send real emails when testing, but to do that, we have to mock the send_mail method away. The problem is, that breaks the rule of never mocking the object under test.
So how can we fix it? We can make a new object which only takes care of sending the actual email:
class MailSender
def send(html)
# send here
end
endNow we can inject the new dependency into our Mailer and mock it as usual:
class Mailer
attr_reader :sender
def constructor(sender)
@sender = sender
end
def send(template, context)
template = find_template(template)
html = template.compile(context)
sender.send(html)
end
end
# in our test
it 'sends the email' do
sender = double
allow(sender).to receive(:send)
mailer = new Mailer(sender)
mailer.send(:welcome_email, name: 'John Doe')
expect(sender).to have_received(:send).with(valid_html)
endUnit Tests Should Be Fast
Another important quality of unit tests is that they should be cheap to run, so they need to run fast. It’s important to have a quick feedback cycle when programming. And when you make a change, you want to know within a few seconds whether it broke something or not. Tools like guard are great for this, as they will run the corresponding spec whenever a file changes.
Some people prioritize speed so much, that their unit tests don’t do slow things such as talking to a database or external service.
Integration Tests
Unlike unit tests, integration tests (also called feature tests or end-to-end tests) plug into the real application. They use the whole stack. The real database, the real services, etc. The more similar this is to our actual application, the better.
Here, we don’t want to mock at all (although some mocking might be necessary), we want to use the real objects as much as possible. And what we want to test, is that our most important paths are properly connected:
For example, for a web application, these kind of tests normally boot up a web browser, a server, send the actual request into the app, and inspect the results.
Integration tests normally only test happy paths. We don’t normally test for failure here, as failure is contemplated in the unit tests. Here, we only care that everything is properly assembled together.
I won’t show you how to write an integration spec as it’s really dependent on your application, but there are great guides out there, and most testing frameworks already support integration tests, so you are far better off checking it out there.
Feature specs are quite slow, so they are normally not run all the time, at least not the whole suite. They are also quite brittle, and cumbersome to write.
Feature tests are important as they are the most honest representation of the actual state of your application.
Should you write mostly feature specs then? It depends. I’ve found out that what works for me is having solid unit tests, and then just checking my objects are properly chained together with a few feature specs, to cover the most important use cases.
But that’s just me. I know classical TDD-ers like to start with an integration test, then write the unit tests for that, then the application code for those unit tests to pass, and all the way back to the feature spec.
If you are doing BDD you will most likely want to document every single use case, and start every feature by writing a feature spec first. Which will most likely include some “sad paths” as well. That will give you great coverage and is also a great way to get your client into testing. The client can, with time, learn to communicate bugs as feature specs, and maybe even write them him/herself, using tools like Cucumber! It also pairs great with DDD.
At the end of the day, you and your team will have to find what works best for each particular project and client.
Continuous Integration
Another common testing practice is Continuous Integration, or CI for short. What CI is all about is configuring a server to run your tests. So, whenever you push code to your repository (GitHub, GitLab, etc) tests are run automatically.
This is great because everyone gets to run their tests in the same environment, reducing possible errors. Also, tests are forced to run after each code change, so there is no way to forget running them!
How this is done exactly varies greatly from place to place, service to service.
Jenkins is a very popular and open source runner you can integrate with GitLab, if you are into hosting everything yourself. For hosted solutions, AppVeyor is able to run Windows, Linux and macOS environments. TravisCI is another popular alternative.
Is that it?
Not at all. Testing is a huge topic, and there’s a lot of information about it, but in my humble opinion, these are the absolute basics every object-oriented programer should know.
The gist of it is, just test what works for you, your team, your client, and your project. There is no silver bullet when it comes to testing.