Sometimes you just need to start over and to take a fresh look at how you are doing things. Many of you know that I usually like to start things anew, but its also understandable that this is impractical at times.
With the release of FileMaker 12, I was inspired to dive deep into how InspectorPro 4 (IP4) was architected and change my way of thinking. It isn’t about REBUILDING per se, but rather this is about RE-THINKING your solutions as you move to FM 12.
At its core, InspectorPro is itself a FileMaker database. The previous version, Inspector Pro 3 (IP3) was originally architected as FileMaker Pro 7 file, and continuously remodeled as we moved all the way through FileMaker Pro 11. InspectorPro 4 on the other hand was built as a FileMaker 12 solution.
I wanted to tell you more about the approach I used. Hopefully it will give you some ideas as you start to re-think, and ultimately rebuild, solutions in FileMaker 12.
Re-thinking InspectorPro 4 in FileMaker 12
In ‘re-thinking’ IP4, with FileMaker 12, I was able to do a number of things. Primarily I was able to dramatically improve performance over IP3. There were a number of contributing factors that led to this improved performance. But one of the core changes was the very extensive use of the new ExecuteSQL function in FileMaker 12.
Here is a side by side census of some of the changes from IP3 to IP4:
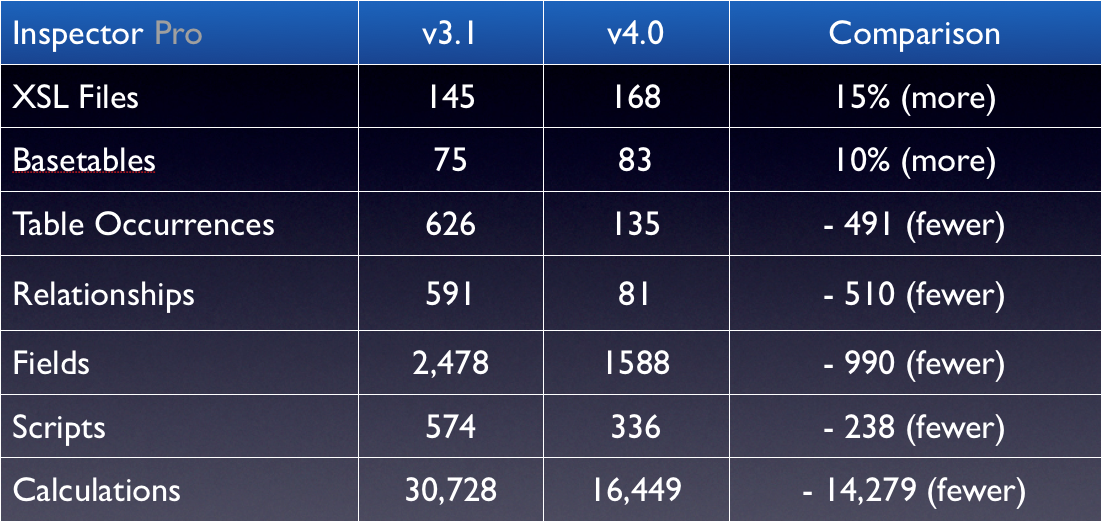
FileMaker 12’s Database Design Report (DDR) outputs more XML metadata than previous versions. IP4 processes this using 13 more XSL Files, and 8 more basetables than IP3.
The big architecture change in IP4 is in the number of Table Occurrences (TOs) that we’re able to do without: 491 fewer.
Removing those TOs ended up removing 510 relationships between them as well. We also managed to make creative use of repeating calculations and drop the number of fields, scripts and calculations significantly.
Here is what the Relationship graph looked like in the older product, IP3 (zoomed out to 25%):
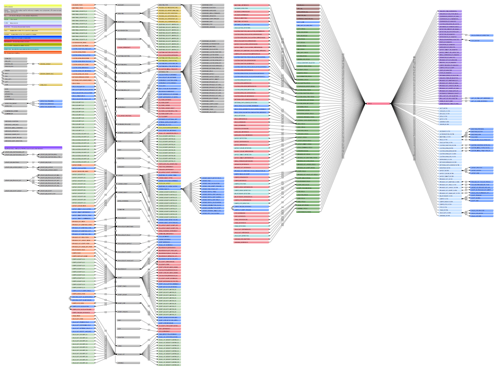
One thing that really jumps out is the DEPENDENCY table. It’s the Grand Central Station of the interconnections between entities.
The big ‘Ah-Ha!’ moment during development was when we realized the bottlenecks in the DEPENDENCY table. It had the largest number of records imported, and had both many text and number fields that were indexed.
Removing almost all the indexed text fields gave us a dramatic boost in performance. So, for example, if a field depends on a value list for validating a field, then a record exists in the DEPENDENCY table to represent this.
With IP3 we stored the DDR IDs of these items, along with the names of the items ( all were indexed ). Similarly if a field could be referenced in a relationship, value list, script step, calculation, or simply on a layout. In each of these cases a record will exist in the DEPENDENCY table to represent this.
So when looking into the dependency table it just means different things from the perspective from which you look.
Trimming the Graph with ExecuteSQL
Once we got rid of so many indexed text fields in IP4, how are we able to show the names of these items? Because we have the DDR ID of the item, we simply relied on ExecuteSQL (2,858 uses of it to be exact) to pull through the name of an item when we need it. Here is an example of pulling the name of an account:
ExecuteSQL ( "SELECT name FROM account WHERE id = " & ACCOUNT_ID & " AND database = 'Contact'" ; "|" ; "¶" )
Here is what the graph looks like in IP4, also zoomed out at 25%:

The end result, as mentioned above, is many fewer table occurrences and relationships. Another big benefit is that this database has fewer elements to track and navigate around. There is simply less code to maintain.
The trade off with this approach, is that it relies on SQL statements. Using this approach, you need make sure these statements are not going to break if you change the names of your fields or tables. But there are great solutions to these challenges. You can use GetFieldName in a Custom Function, and by doing so you get the added benefit of knowing that this field is referenced by the ExecuteSQL function.
You also need to be comfortable with SQL. Don’t worry…there are already some great resources available inside the FileMaker community for learning more about SQL. Here’s a good summary of FileMaker 12 Execute SQL resources.
When FileMaker 7 was introduced there was so much new in that release that I often thought that ‘Rebuilding’ was the way to go. But after talking to many people over the years about their solution I have realized that sometimes that is an impossible and overwhelming task. Indeed, it is. So now the way I look at it is instead of ‘Rebuilding’ I like to think of it as ‘Re-Thinking’. You can start over and look at what you had before … move it into place, rework it slightly, or rebuild it using new techniques that you have learned.
From Worst To Best
One of my favorite sayings is: “The worst developer is me, 2 years ago”. Hopefully your skills improve over time (attending conferences, user groups, mailing lists, forums, etc.…). FileMaker gains new features, like ExecuteSQL, where simply a shift in adopting a new feature can lead to dramatic changes. Plus sometimes it’s essential to do some spring cleaning and lighten things up.
With FileMaker 12 there are so many ways you can ‘Re-Think’ your databases. There’s now support for External Container Fields, the new Layout Object Design Surface, many enhancements in the new FileMaker Server 12, and a new version of FileMaker Go (free) where you can build mobile solutions.
I invite you to ‘Re-Think’ your solutions and hopefully free yourself from database baggage you don’t need to keep carrying along. The result may be less code, that’s easier to manager, and better solutions, that are easier and faster to debug. And hopefully you’ll have more time to enjoy with family and friends.
Thanks!
— Vince
Vince Menanno is the creator of InspectorPro and Director of FileMaker Development at Beezwax.