The pandas library for Python has become a go-to tool for many data scientists and analysts. In this blog post, we’ll examine one strategy for leveraging the highly powerful tools within pandas to enhance data analysis capabilities using the Claris FileMaker platform. We’ll do this by calling the bBox plugin and its built-in Python functions.
Augmenting FileMaker’s Capabilities, Externally
First off, let me say that the FileMaker Platform is many great things: quick to learn, quick for prototyping fully-functional apps, relatively easy to deploy, with capacity to hold terabytes of text and binary data. What FileMaker isn’t though, is efficient with analyzing very large data sets. Well, at least it’s not efficient compared to some of the other platforms and programming languages. If you have ever tried to manipulate a JSON object of 50,000 elements or summarize a record set of over 1,000,000 records in multiple ways, using FileMaker, you have experienced that.
To bridge that gap, one way is to reach outside of FileMaker to other programming languages and utilize some of their common libraries. Enter the pandas data analysis toolkit for Python.
Here is how pandas describes itself:
pandas is a Python package that provides fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive…[with] the broader goal of becoming the most powerful and flexible open source data analysis / manipulation tool available in any language.
source: pandas: What is it?
This is a lofty goal. And, to many in the data science community, pandas has already achieved this.
There are a few things we can do very efficiently with pandas on very large (FileMaker) datasets:
• Convert your entire dataset to a JSON array of objects.
• Export your dataset as CSV or Excel with additional calculated columns and custom column headers.
• Summarize your dataset by one or multiple columns.
• Quickly describe your dataset, returning mean, median, min, max, and standard deviation of all numerical fields.
This only scratches the surface. The list goes on and on. So I’ll cut to the chase, and show an example.
Leveraging pandas with FileMaker
First off, the basic concept for leveraging pandas with your FileMaker database goes like this:
- Export the dataset as an XLSX file (the FMP temporary path works just fine).
- Call executable code in Python via bBox plugin for FileMaker.
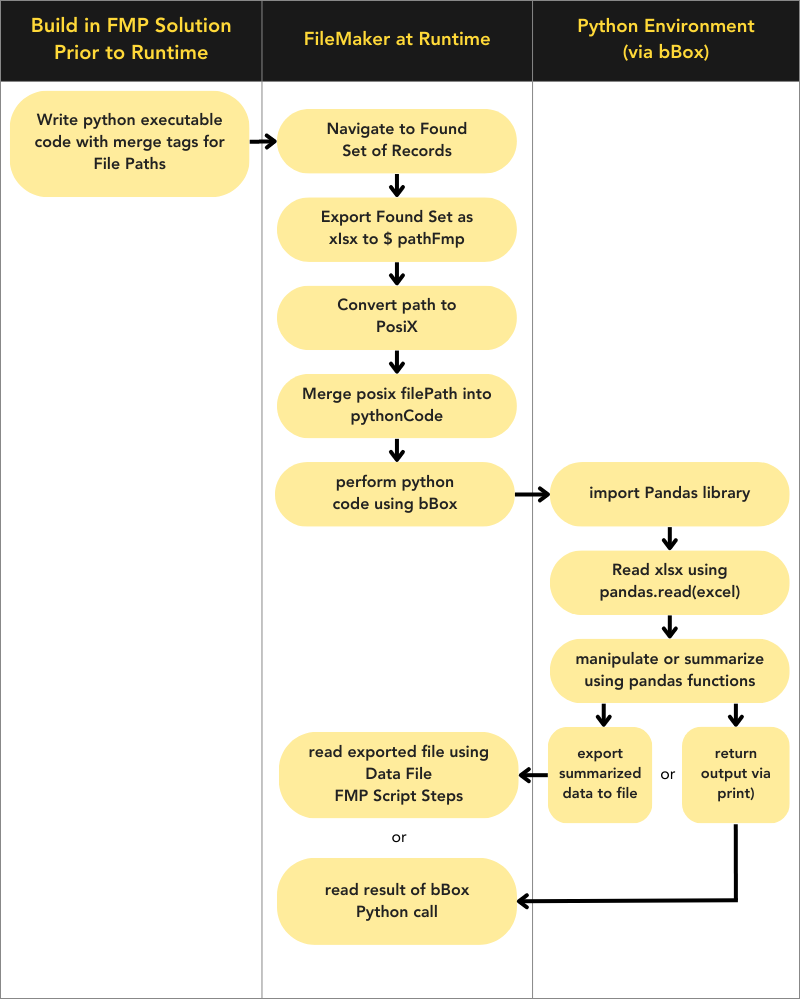
The following steps will be within Python using bBoxPython3Run() called from FileMaker. You will have to craft this Python code ahead of time, passing any file path as POSIX (and, luckily, there’s a function for that).
- Import the pandas library.
- Read the XLSX file (from the POSIX path) into a pandas DataFrame.
- Perform some pandas manipulation or summarization on the DataFrame.
- Return the results back to FileMaker in one of two ways:
a.print()the results as part of your Python code. Whatever you print within Python will be the returned result of thebBoxPython3Run()function.
or –
b. Use pandas to export another file: csv, xlsx, json, etc. Then, after the Python call is completed, read the file using FileMaker’s Data File script steps.
NOTES:
- The examples below, and those included in the demo file, use the
bBox_Python3Run()function in a system where pandas has already been installed on the Python3 environment. - The demo file does contain code to install pandas and other libraries you may be lacking.
- The sample file uses the well-known “SuperStore” data set which can be found many places online.
Example 1: Convert Entire Dataset to JSON:
- Export the found set to an xlsx file in the temporary directory.
- Convert both the xlsx file path and the output JSON file path to POSIX and merge that value in your Python code.
- Within bBox’s Python perform the following:
i. Import pandas library.
ii. Write the exported xlsx file to a pandas DataFrame usingpandas.read_excel().
iii. Convert the DataFrame to JSON usingpandas.to_json().
iv. Either print () the JSON to return as a result ofbBox_Python()
– or —
v. Write the JSON usingfile.write()to specified location. - If written as a file, write the file to the database using FileMaker’s Data File script steps.
Example 2: Export with a Calculated Column and Renamed Column Headers:
- Export the found set to an xlsx file in the temporary directory.
- Convert both the xlsx file path and and resulting file’s path to POSIX and merge that value in your Python code.
- Within bBox’s Python perform the following:
a. Import pandas library.
b. Read the exported xslx file to a pandas DataFrame usingpandas.read_excel().
c. Rename columns usingpandas.rename().
d. Set a new column pandas[‘New Column’] = a calculation based on one or more column ( pandas[‘A to B Ratio’] = pandas[‘A’]/ pandas[‘B’].
e. Export the new DataFrame as an Excel fileusing pandas.to_excel(). - Read that file into the database using FileMaker’s Data File script steps and store to a container field.
Example 3: Describe the Numerical Data in the Dataset (mean, median, min, max, stddev)
- Export the found set to an xlsx file in the temporary directory.
- Convert both the xlsx file path and and resulting file’s path to POSIX and merge that value in your Python code.
- Within bBox’s Python perform the following:
a. Import pandas library.
b. Write the exported xslx file to a pandas DataFrame usingpandas.read_excel().
c. Create a describing DataFrame usingpandas.describe(). - optional* – Export the newly created describing DataFrame as an Excel file using
pandas.to_excel(). - optional* – Write that file into the database using FileMaker’s Data File script steps and store to a container field.
* Note:pandas.describe()returns just the summary stats, so it should be faster just to use the returned value.
Example 4: Summarize by a Combination of Two Attributes:
- Export the found set to an xlsx file in the temporary directory.
- Convert both the xlsx file path and the output file’s path to POSIX and merge those values into your Python code.
- Within bBox’s Python perform the following:
a. Import pandas library.
b. Read the exported xslx file to a pandas DataFrame usingpandas.read_excel().
c. Summarize the data to another DataFrame usingpandas.groupby().to_frame().
d. Export the newly created summary DataFrame as an Excel file usingpandas.to_excel(). - Read that file into the database using FileMaker’s Data File script steps and store to a container field
Example file: pandas for FileMaker Data Sets
You can examine these use cases in the example file, using the well-known SuperStore data set.
Download: pandas_for_FM_Data_Sets.fmp12 [FileMaker file; 14.1 MB]
Workflow
Here’s a flowchart of the workflow for leveraging pandas with Python using FileMaker, including the bBox plugin:
Bonus: Starring bBox with JavaScript
The bBox plugin is awesome for many, many reasons beyond just its ability to call Python, both on client and on the server (if your environment allows). Another is bBox’s ability to call JavaScript (on client and on server) without the need of a FileMaker web viewer.
2 thoughts on “Leveraging pandas with Python to Analyze FileMaker Data Sets”
Comments are closed.